El aprendizaje automático acelera las simulaciones de modelos climáticos a resoluciones más finas a nivel local
Los científicos encuentran que el aprendizaje automático para utilizar los beneficios de los modelos climáticos actuales, al tiempo que reducen los costos computacionales necesarios para ejecutarlos
Los modelos climáticos son una tecnología clave para predecir los impactos del cambio climático. Al realizar simulaciones del clima de la Tierra, los científicos y los responsables de la formulación de políticas pueden estimar condiciones como el aumento del nivel del mar, las inundaciones y el aumento de las temperaturas, y tomar decisiones sobre cómo responder adecuadamente. Pero los modelos climáticos actuales luchan por proporcionar esta información de manera suficientemente rápida o asequible para que sea útil en escalas más pequeñas, como el tamaño de una ciudad.
Ahora, los autores de un nuevo artículo publicado en el Journal of Advances in Modeling Earth Systems han encontrado un método para aprovechar el aprendizaje automático para utilizar los beneficios de los modelos climáticos actuales , al tiempo que reducen los costos computacionales necesarios para ejecutarlos.
"Le da la vuelta a la sabiduría tradicional", dice Sai Ravela, investigador principal del Departamento de Ciencias de la Tierra, Atmosféricas y Planetarias (EAPS, por sus siglas en inglés) del MIT, quien escribió el artículo con la postdoctorada de la EAPS Anamitra Saha.
Reducción de escala espacial con aprendizaje automático: ventajas y beneficios
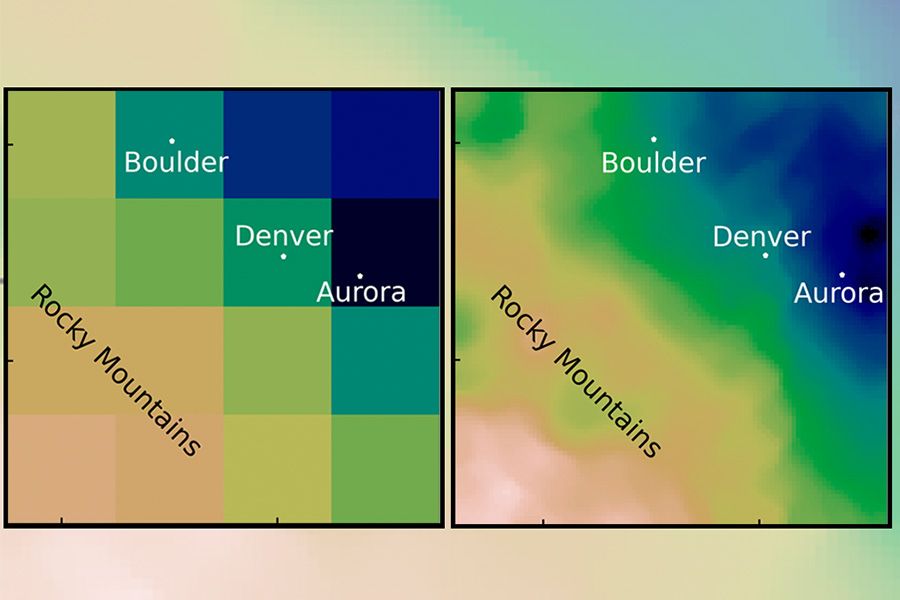
En el modelado climático, la reducción de escala es el proceso de utilizar un modelo climático global con resolución gruesa para generar detalles más finos en regiones más pequeñas. Imagine una imagen digital: un modelo global es una imagen grande del mundo con un número reducido de píxeles. Para reducir la escala, hace zoom solo en la sección de la foto que desea ver (por ejemplo, Boston). Pero debido a que la imagen original era de baja resolución, la nueva versión está borrosa; no proporciona suficientes detalles para ser particularmente útil.
"Si se pasa de una resolución gruesa a una resolución fina, hay que añadir información de algún modo", explica Saha. La reducción de escala intenta volver a agregar esa información completando los píxeles que faltan. "Esa adición de información puede ocurrir de dos maneras: puede provenir de la teoría o de los datos".
La reducción de escala convencional a menudo implica el uso de modelos basados en la física (como el proceso de elevación, enfriamiento y condensación del aire, o el paisaje del área) y complementarlos con datos estadísticos tomados de observaciones históricas. Pero este método es exigente desde el punto de vista computacional: requiere mucho tiempo y potencia informática para ejecutarlo, y al mismo tiempo es costoso.
En su nuevo artículo, Saha y Ravela han descubierto una manera de agregar los datos de otra manera. Han empleado una técnica de aprendizaje automático llamada aprendizaje adversarial. Utiliza dos máquinas: una genera datos para la foto. Pero la otra máquina juzga la muestra comparándola con datos reales. Si cree que la imagen es falsa, la primera máquina debe intentarlo de nuevo hasta convencer a la segunda. El objetivo final del proceso es crear datos de superresolución.
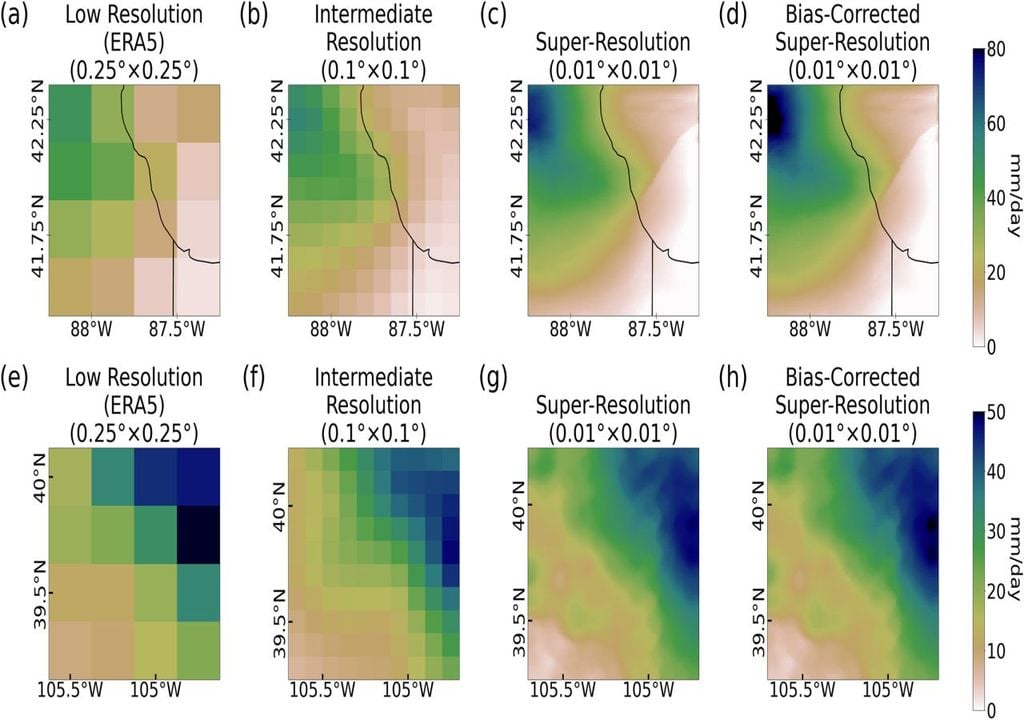
El uso de técnicas de aprendizaje automático como el aprendizaje adversario no es una idea nueva en el modelado climático; donde actualmente tiene problemas es su incapacidad para manejar grandes cantidades de física básica, como las leyes de conservación. Los investigadores descubrieron que simplificar la física y complementarla con estadísticas a partir de datos históricos era suficiente para generar los resultados que necesitaban.
Los autores comenzaron estimando cantidades extremas de lluvia eliminando ecuaciones físicas más complejas y centrándose en el vapor de agua y la topografía terrestre. Luego generaron patrones generales de lluvia tanto para la montañosa Denver como para la plana Chicago, aplicando relatos históricos para corregir los resultados.
"Nos está dando extremos, como lo hace la física, a un costo mucho menor. Y nos está dando velocidades similares a las estadísticas, pero con una resolución mucho mayor", continúa Ravela.
Otro beneficio inesperado de los resultados fue la poca información de entrenamiento que se necesitaba. "El hecho de que sólo un poco de física y un poco de estadística fuera suficiente para mejorar el rendimiento del modelo ML [aprendizaje automático]... en realidad no era obvio desde el principio", dice Saha. Solo lleva unas pocas horas entrenarlo y puede producir resultados en minutos, una mejora con respecto a los meses que tardan otros modelos en ejecutarse.
Cuantificar el riesgo rápidamente
Ser capaz de ejecutar los modelos con rapidez y frecuencia es un requisito clave para las partes interesadas, como las compañías de seguros y los formuladores de políticas locales. Ravela da el ejemplo de Bangladesh: al ver cómo los fenómenos meteorológicos extremos afectarán al país, se pueden tomar decisiones sobre qué cultivos se deben cultivar o hacia dónde deben migrar las poblaciones, considerando una gama muy amplia de condiciones e incertidumbres lo antes posible.
"No podemos esperar meses o años para poder cuantificar este riesgo", afirma. "Es necesario mirar hacia el futuro y a un gran número de incertidumbres para poder decir cuál podría ser una buena decisión".
Si bien el modelo actual solo analiza las precipitaciones extremas, el siguiente paso del proyecto es entrenarlo para examinar otros eventos críticos, como tormentas tropicales, vientos y temperatura. Con un modelo más sólido, Ravela espera aplicarlo a otros lugares como Boston y Puerto Rico como parte de un proyecto Climate Grand Challenges del MIT.
Referencia
Anamitra Saha et al, Statistical‐Physical Adversarial Learning From Data and Models for Downscaling Rainfall Extremes, Journal of Advances in Modeling Earth Systems (2024). DOI: 10.1029/2023MS003860